纯cpu跑大模型,linux部署deepseek-r1 70b q4,纯娱乐

最近在自己服务器上部署了下deepseek-r1 70b q4大模型,不过我肯定是没显卡,就用纯cpu来跑,顺便写个简单的教程。
先科普下上面的名词,deepseek-r1是模型参数,最近火爆的deepseek就是这个模型(以及迭代);70b指的是参数。b代表亿,说明这个是70亿的参数,参数越大,需要消耗越多算力(还需要更多的存储空间、内存容量)但也更智能;q4指的是量化,有q8 fp16等等,是指的量化,q8也要比q4消耗更多资源同时也更准确。那我这里就直接使用ollama部署了,什么,为什么要使用这个,因为简单,不用动脑子。
一、准备系统
为了性能最大化,建议是直接裸机部署,不过我这里就是在用的lxc部署的,记得系统选择debian这种,如果是alpine就不行,因为不兼容libc,嗯我一开始就是用alpine,下载了半天才发现装不上.....为什么不用windows?因为windows系统本身就要比linux吃性能。
当然也可以选择docker,不过我这是proxmox,不好直接用docker,一般家庭服务器也不太会直接裸机用docker,都是在虚拟机里面,相当于做了次套娃,而跑ai本来就吃性能,所以能裸机部署就裸机部署。
二、部署ollama&运行模型
这个其实没啥好说的,直接输入以下命令,运行就完事了:
curl -fsSL https://ollama.com/install.sh | sh
#安装ollama
ollama run deepseek-r1:70b
#运行模型

第一步安装ollama的时候建议上科技,第二步下载模型并运行就不用了,国内速度很快,最快可以70MB/s,不过后面会降速,结束并重新拉取下载就可以恢复速度了。

结束对话就按ctrl+d结束,需要再次运行就重新输入上面第二条命令,此时不会重新拉取会直接运行。
三、效果
emmmm我要怎么说呢,家庭玩这个纯属图一乐,没高性能设备撑不起来的,我这相当于四通道ddr4内存,16核的cpu,跑70b差不多一秒一个字,谁受得了啊,当然也可以运行更轻量化的模型,例如1.5b,但是我为什么不直接用现成的api呢,除非你家里有十几个卡,那确实可以玩,不然老老实实用现成api。家里有服务器多卡的大佬当我没说。
就光70b内存都要吃掉50g,当然如果上下文越多也越吃内存,不过主要是内存带宽限制了,cpu没都没法跑满。
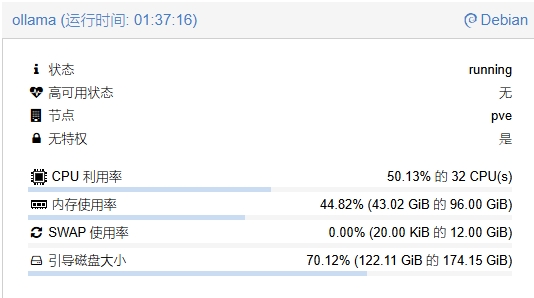
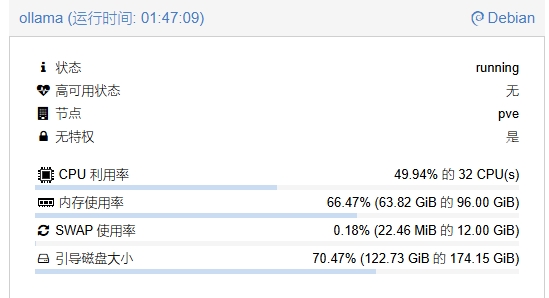
那就得说一下这个性能需求了,最简单的,高内存带宽,高cpu性能,大内存,特别是671b,内存没到512g的不用看了(我也不知道够不够,应该是够的吧),就算70b也得需要64g;还有最重要的内存带宽,带宽越大越好,12通道ddr5内存安排上,不过需要提醒下,如果是双路epyc,记得调优,不然因为节点问题双路性能还不如单路......。至于最重要的cpu性能不用说都明白。